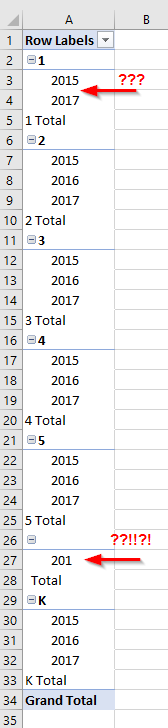Our English Language Development department wants to track students who are considered “former English learners” in Illuminate. The criterion is if they’ve been exited from the EL program within the last four years. This requires a few preparations.
First, set the code within Illuminate to display the former EL status. I just chose the next one available. I’ll use this variable in my SQL script, which comes next.
From the cog, choose Code Management
Look for English Proficiency. I just start typing “english,” and it appears:
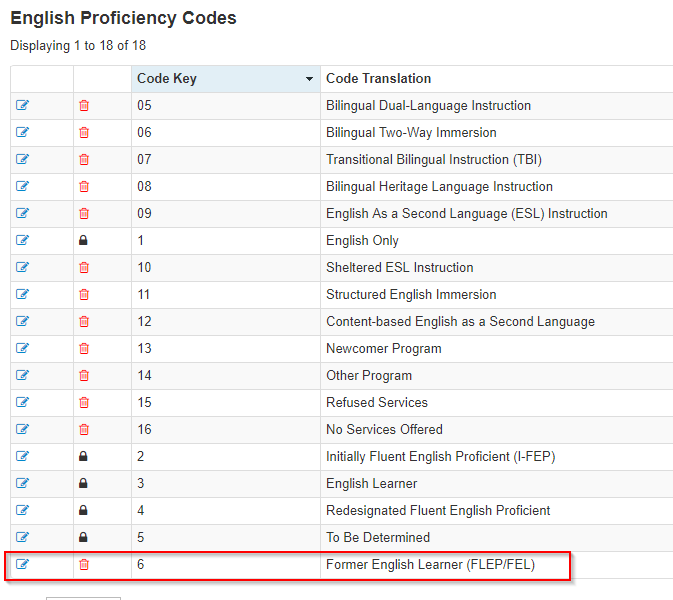
Then add the new code. In our case, plain number 6 was the next available one. I have to remember this value:
Next, I need to edit studemo.sql on the server where the SQL extract scripts are installed. These are the scripts that build queries from the PowerSchool database, assemble the files, and then SFTPs them to Illuminate’s server.
The column that provides English proficiency status is column 14. For that column, I use a CASE statement:
case
when (sc.flaglep = 1) then 3
when (sc.lepexitdate > to_date('6/15/'||to_char(extract(year from sysdate)-4),'mm/dd/yyyy')) then 6
else null end
The prefix sc refers to an alias for our state reporting code. PowerSchool users outside of Michigan may have different column names. Walking through this CASE statement, here’s what I’m saying:
- If the “is an English learner” checkbox is marked, the value is 1 in the database, so I want to return the value of 3 to send to Illuminate (note in the screen shot above of the code table, where 3 indicates “English Learner”).
- If the EL exit date is greater than a date of June 15 of the year that’s 4 earlier than the current system date, then return a 6.
- Otherwise, return nothing
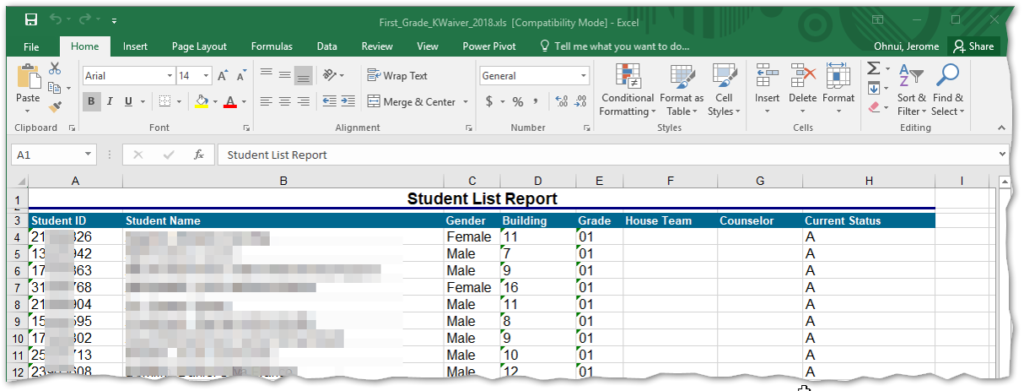
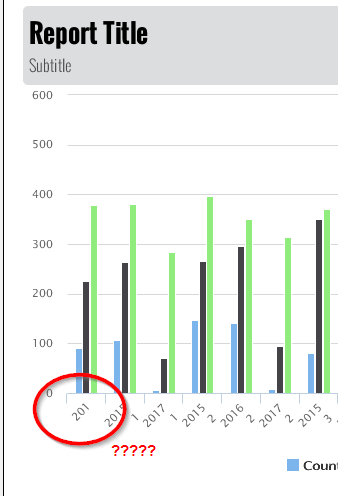
So the possible output values will be 3, 6, or nothing. This is proven when looking at studemo.txt in Excel:
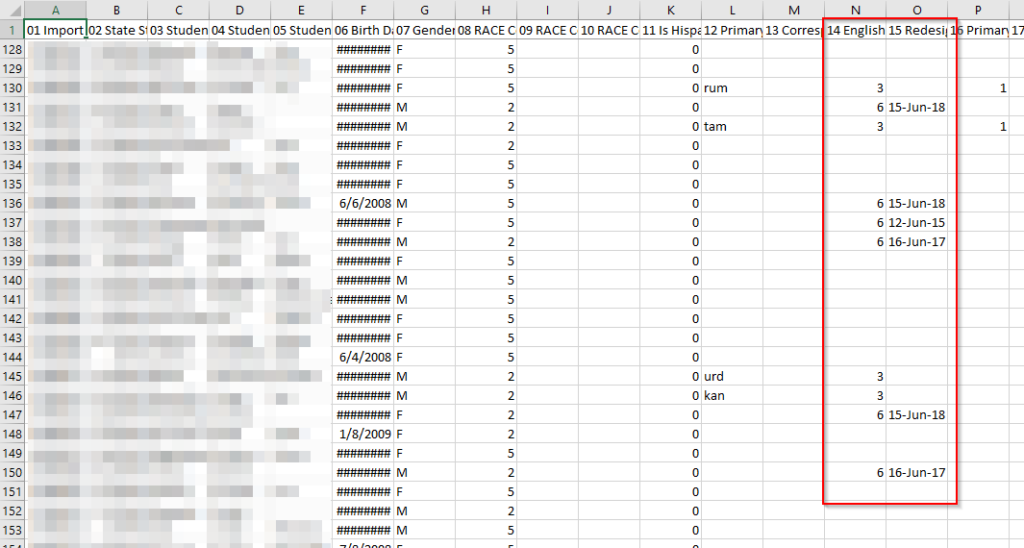
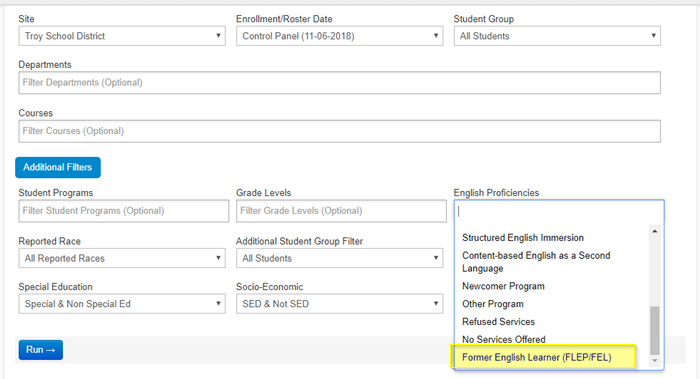
Once uploaded to Illuminate, this value can then be used in filters for reports, student groups, and assessments: